We claim that Madeleine is an interesting candidate to serve as a medium-level programming interface for VIA when used in the framework of distributed multithreaded applications. Thus, we have developed a preliminary implementation of Madeleine on top of VIA. It is designed to hide all aspects of flow control to the application programmer and provides an optimal strategy with respect to the given semantic flags: SEND_SAFER, etc. As it is specifically used within a multithreaded environment, Madeleine automatically overlaps communication with computation if possible. Several threads can issue a send request concurrently. As soon as a thread gets blocked within the internal protocol, Madeleine issues a scheduling request to the multithreading environment. Moreover, Madeleine can dynamically select the best completion signaling strategy as a function of the current status of the existing threads (polling vs. interrupts). Finally, Madeleine implements both a static message transmission policy for small messages and a dynamic transmission policy for large messages as shown in Section 1.4.
The implementation of the portability layer on top of VIA was rather straightforward because gather/scatter functionalities are provided through the descriptor management. We rather provide details about the two alternative implementations of message transmission.
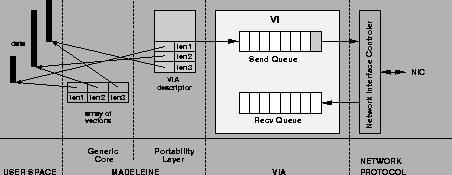
Figure 4 shows the typical execution path followed in sending of a large message formed out of, for instance, three vectors.
The Madeleine generic message management code first builds an array describing the message. This array is passed to the portability layer which is VIA specific. A single VIA descriptor is then built by simply copying the three entries of the array of vectors. Then, the memory areas containing the user data are registered in VIA. Finally, the descriptor is posted in the Send Queue through an asynchronous operation and the current thread yields the processor until the operation has completed. Upon completion, the user data is unregistered.
In fact, the real implementation of a message transmission is slightly more elaborate as VIA does not provide flow-control. Thus, before a descriptor can be posted in a Send Queue, one has to make sure that a corresponding descriptor has already been posted in the destination Receive Queue. Madeleine uses acknowledgment messages to control the posting of message bodies. A simple credit-based algorithm is used so that explicit acknowledgment messages can be avoided in many situations.
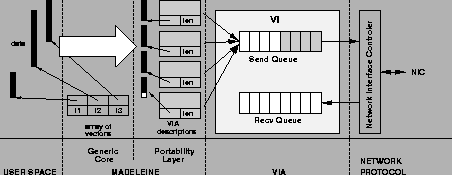
For small messages, we have adopted a strategy similar to the one presented in Section 1.4. A pool of pre-registered static buffers is allocated once at initialization time within the portability layer. The User messages are systematically copied into these buffers before being sent through VIA. As a result, four (un)registration operations are saved when transferring a single piece of user message. The consequence is an additional copy of data, which can however be partially overlapped by pipelining the processing of the various buffers. Figure 5 summarizes this strategy.
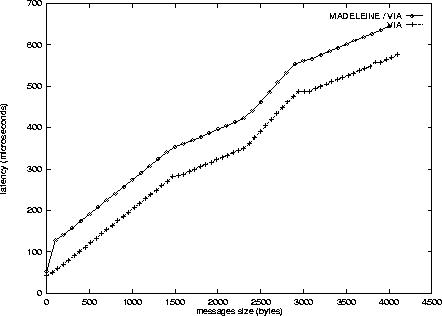
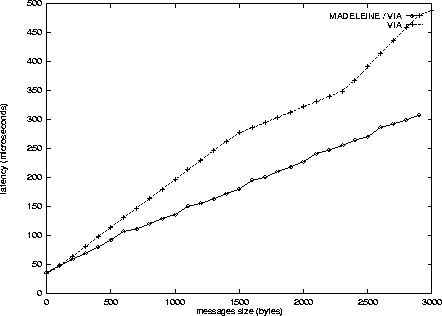
As an overall validation of our implementation, we measure the overhead of this implementation of Madeleine relatively to VIA. We run a simple ping-pong test written on top of Madeleine. The measurement is done on our Fast-Ethernet cluster. Two implementations of Madeleine are compared against their ``raw'' VIA counterparts: the dynamic 0-copy one (Section 3.1, Figure 6) and the static register-once one (Section 3.2, Figure 7).
 |
 |
On Figure 6, the Madeleine
implementation shows a constant overhead with respect to VIA, of the
order of 75 ![]() s. This is due to the additional flow control messages
which are needed by Madeleine to make sure that a descriptor has
already been posted on the receiving side. Two small successive
messages are exchanged, one in each direction. Each of them takes about
35
s. This is due to the additional flow control messages
which are needed by Madeleine to make sure that a descriptor has
already been posted on the receiving side. Two small successive
messages are exchanged, one in each direction. Each of them takes about
35 ![]() s, which appears to be the basic latency time to send a single
message with no data, as shown on Figure 7
where no memory registration is performed. In the case of a very
small message, the latency is 53
s, which appears to be the basic latency time to send a single
message with no data, as shown on Figure 7
where no memory registration is performed. In the case of a very
small message, the latency is 53 ![]() s. As the data are directly stored
by VIA in the message header, no descriptor is needed on the receiving
side, and only one VIA message is used. One only pays for the memory
registration of one memory page on each side, which takes another
10
s. As the data are directly stored
by VIA in the message header, no descriptor is needed on the receiving
side, and only one VIA message is used. One only pays for the memory
registration of one memory page on each side, which takes another
10 ![]() s or so. Observe that the throughput of Madeleine is about the
same as that VIA.
s or so. Observe that the throughput of Madeleine is about the
same as that VIA.
On Figure 7, we observe an exciting result: Madeleine on top of VIA outperforms VIA! A finer analysis reveals the following phenomenon.
We should also stress that these figures have been obtained with a simple ping-pong test with only a single thread on each side. An additional overlap with the other computing threads is gained from the scheduling, in contrast with more realistic experiments. We conjecture that the Madeleine/VIA and VIA would achieve comparable overheads in the presence of other working threads. We are currently working out such additional experiments.