The research on communication interfaces has already demonstrated that a user-level approach [14,8,9] cannot be avoided to achieve high performance (minimal latency, maximal bandwidth). From this viewpoint, the model defined by VIA originates in some pioneers of user-level communication interfaces such as U-Net [13] or Active Messages [14]. From a technical point of view, one of the main contributions of VIA is to provide a clean specification of the interactions between the operating system and the user-level communication level.
The Virtual Interface (VI) is the core concept of VIA. It allows a user program to perform message passing operations. A VI consists of a pair of message queues: a send queue and a receive queue. The user program posts emission or reception requests on the message queues to send or receive data. A request consists of a descriptor describing work to be done by the network interface controller. It includes a control segment and variable number of data segments (scatter-gather descriptors). Each queue manages a separate linked-list of descriptors. VIA also provides a completion queue construct used to link completion notifications from multiple work queue to a single queue. A user process can own many VIs, one for each point-to-point bidirectional connection. The kernel agent defines the mechanisms needed to establish the connections between nodes, in cooperation with the operating system.
Most parallel applications need some form of flow control for communications. Usually, this flow control is implemented at the network protocol level, so that the higher level libraries do not have to bother about this problem. However, doing so freezes the flow control policy and may generate communication overhead, for instance because unnecessary acknowledgment messages may be transmitted at the lowest level.
For this reason, the VIA interface does not provide any flow control functionality and this is up to the higher-level software layer to implement it. Although this guarantees that the application has a tight control about the data transmissions, this also complicates a lot the application code. Again, the flexibility of the low-level VIA interface leaves the programmer with a challenging burden. Adding a medium-level software layer on top of VIA could at least provide the programmer with some default parameterized solution.
Overlapping communication and computation is an old technique to improve performance, it has been used in both applications and parallel libraries. The programming interface of the underlying system is a critical point in the use of this technique. Its layout and semantics set the limit of what a particular implementation is able to achieve. If the API splits the blocking communication operations into a pairs of start and completion sub-operations, as in MPI [12], then some computation can be overlapped in-between. Yet, this is efficient only if the low-level protocol is handled by some kind of additional communication processor (possibly embedded in the NIC as in Myrinet), or if the system provides some efficient way to switch from the main computation to the execution of the underlying protocol, driven for instance by the hardware interrupts.
The VI architecture provides the application with an asynchronous interface to the network. The asynchronous operations provided by VIA operations are very similar in spirit to the non-blocking operations of MPI. A program can post a descriptor onto the message queue of a VI without blocking. The completion of a send or receive operation by the network controller is signaled by flipping a status field in the user descriptor. Since the descriptors live in the virtual user space, the completion can be checked without any system call (polling).
The main advantage of the polling mechanism is to reduce the cost of managing completions, especially when the network is loaded with a high number of messages. The drawback is a lack of responsiveness when the CPU is busy, as the polling activity may be delayed. The opposite choice is then to use an interrupt which is raised at the communication completion. This interrupt is generated by the VI kernel agent and involves the operating system. The computation thread is suspended and a handler function is called to process the completion. Unfortunately, the interrupt mechanism induces costly interactions with the operating system.
As a conclusion, handling messages asynchronously to overlap communication with computation is a difficult and sensitive challenge [7]. The overall performance of the application crucially depends on a large number of implementation choices. VIA provides the programmer with a number of alternative mechanisms and a tight control on their management. However, selecting the optimal trade-off among them is a task requiring expert knowledge, which should be encapsulated into a medium-level software layer.
Communication protocols usually involve memory copies of transmitted data: the data is first copied from the user space to the kernel space, then copied from the kernel space to the on-board memory of the NIC, and finally transmitted through the network. Since the cost of a memory-to-memory copy is nowadays of the same order of magnitude as a network transfer, such protocols induce an unacceptable overhead. VIA, as many other contemporary network protocols (BIP [9], Active Messages [14], etc.) has been designed to avoid unnecessary memory copies between the user application and the network card controller: the data are directly transferred by a DMA mechanism. This implies in turn that the memory area is first registered to ensure correct co-operation between the paging activity of the operating system and the activity of network driver or network firmware which manipulates the physical location of the data.
Explicit registering memory areas is a new concept introduced in VIA. The U-Net/MM [1] was doing this transparently and automatically when needed. Systems like BIP do it transparently in the communication user-level library when needed, avoiding the cost of registration when a copy can provide better performance (for small messages for instance, or by managing a cache that takes into account the underlying implementation). In contrast, it is up to the programmer to explicitly specify when and how memory areas are registered in VIA.
This additional degree of freedom provided by VIA may in fact become most challenging, as VIA provides no hints about what a particular implementation is able to do. For some implementations, registration may induce a large overhead in time but little in resources: the best choice may be to register all memory areas just once. For other, registering and unregistering memory areas on each use, possibly with some sort of registration cache, may be the best solution. Explicitly hand-coding this choice into the application hinders their portability. Their performance becomes highly dependent of features deeply hidden in the underlying operating system. Again, the programmer is left with a freedom which may prove more embarrassing than helpful. An intermediate medium-level software layer is definitely needed.
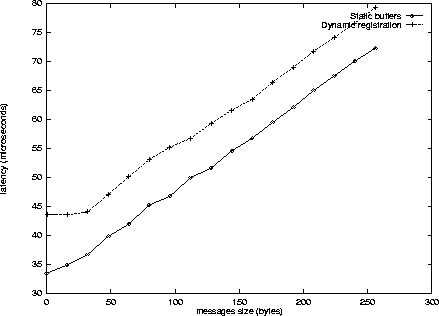
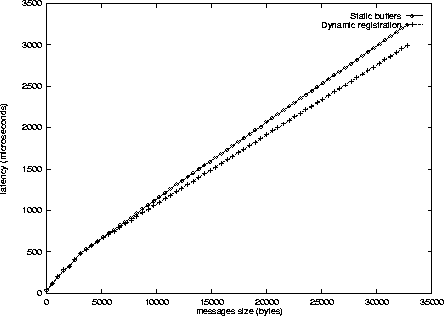
The experiments have been carried out on two Intel-based nodes (dual Pentium-II 450 Mhz, 440BX chipset) connected by a 100 Mb/s Fast-Ethernet network (21140-based Ethernet cards). We have used the M-VIA implementation of VIA developed at Berkeley (http://www.nersc.gov/research/FTG/via/). Figure 1 displays the performance (latency) of the two alternatives for small messages (up to 256 Bytes). One can notice that for such messages, the dynamic memory registration is prohibitive and exceeds the cost of the corresponding memory copies. Figure 2 does the same for larger messages (up to 32 kB). Clearly, when messages get larger, the dynamic approach outperforms the static one because the cost of the copies become dominant. In this experiment, the crossing point is reached for 3 kB messages.
This toy experiment shows that the static policy should be used for smaller messages, and that the dynamic one should be used for larger ones. Clearly, the precise crossing point is highly dependent on a large number of parameters associated with the the operating system, the NIC, the chipset, etc. It is definitely not a good idea to let the application programmer bother with such details. Ideally, an additional medium-level communication interface should encapsulate a clever mechanism that would switch from one policy to the other depending on the message.