
Key words: computing system, network, parallel processing, data sorting, quicksort.
Data sorting is the most studied problem in computer science, for both, its theoretical importance and its use in so many applications.
A parallel sorting algorithm on a heterogeneous system - PC cluster was implemented to minimize the application execution time. In this paper we propose a scheme for communicating data among subtasks during application program execution.
We present some experimental results of the parallel sorting algorithm on a PC cluster.
There is a continual demand for greater computational speed from a computer system than currently possible [17]. Areas requiring great computational speed include numerical modeling and simulation of scientific and engineering problems. Such problems often need huge repetitive calculations on large amounts of data to give valid results.
In network-based computing environment, several computers are linked through a communication network to form a large loosely coupled distributed network [6]. One of the major attributes of such a distributed system is the capability that it offers to the user of a single node to exploit the considerable power of the complete network or a subset of it by partitioning and transferring its own processing load to other processors in the network. This capability is useful in handling large computational loads.
Communication latency is an important factor in deciding performance of a parallel or distributed algorithms, especially in a low speed network or in a communication-intensive task situation [12].
In this paper we are concerned with the problem of distributing a single large load that originates at one of the nodes in the network. The load is massive compared to the computing capability of the node. Hence, the processor partitions the load into many fractions, keeps one of the fractions for itself to process, and sends the rest to its neighbours (or other nodes in the network) for processing. When the processing at each node is completed, partial solutions are gathered and consolidated at the load originating processing to construct the complete solution. An important problem here is to decide how to achieve balance in the load distribution between processors, so that the computation is completed in the shortest possible time [6]. Applications that satisfy divisibility property include processing of massive experimental data, image processing applications like feature extraction and edge detection, signal processing applications such as computation of Hough transforms.
In this paper we present a sorting algorithm on a heterogeneous computing system [3, 10, 14, 17]. The heterogeneous computing system (PC cluster) is used to minimize the program execution time. It is based on the message passing between computers. A realistic bus-oriented network (Ethernet) with multicast type of communication regimen is considered. Heterogeneous computing includes both parallel and distributed processing. The purpose and the advantages of using a heterogeneous computing system are presented.
Data sorting [2, 15, 9, 13, 11, 8, 16] is the most studied problem in computer science, for both, its theoretical importance and its use in so many applications. The parallel sorting method, or sorting strategy, on a one-dimensional sub-bus array of processors is presented in [5, 4].
The rest of the paper is organized as follows. In Section 2 an overview of the estimated speedup of parallel sorting algorithms is given. In Section 3 a parallel sorting algorithm on a PC cluster is described. Experimental results of the implemented parallel algorithm on a parallel computing system are presented in Section 4. In Section 5 the conclusion remarks are given.
While writing a parallel program a question about the quality of the program arises. There are two ways of evaluating a parallel program. The relation between time complexity of a sequential and a parallel algorithm is known a as speedup and it is defined as [17]:
where t1 is the execution time on a single processor and tp is the execution time on a multiprocessor, and p is the number of processors. In the best case scenario of the speedup would be

which is not possible in the real world. There are many reasons:
The next metric of the parallel algorithm is program efficiency and it is defined as

Algorithm efficiency is the relation between time complexity of the sequential program and time complexity of the parallel algorithm multiplied by the number of processes.
In this section theoretical aspects of the speedup of a parallel sorting algorithm is described.
Consider the following parallel quicksort algorithm [15]. A number of identical processes, one per processor, execute the parallel algorithm. The elements to be sorted are sorted in an array in global memory. A stack in global memory stores the indices of sub-arrays that are still unsorted. When a process is without work, it attempts to pop the indices for an unsorted sub-array, based on a supposed median element into smaller arrays, containing elements less than or equal to the supposed median value or greater than the supposed median value, respectively. After the partitioning step, identical to the partitioning step performed by the serial quicksort algorithm, the process pushes the indices for one sub-array onto the global stack of unsorted sub-arrays and repeats the partitioning process on the other sub-array. What speedup can be expected from this parallel quicksort algorithm? Note that it takes comparisons k - 1 to partition a sub-array containing k elements. The expected speedup is computed by assuming that one comparison takes one unit of time and finds the ratio of the expected number of comparisons performed by the sequential algorithm to be expected time required by the parallel algorithm. To simplify the analysis, assume that n = 2 k - 1 and p = 2 m , where m < k . Also assume that the supposed median is always the true media so that each partitioning step always divides an unsorted sub-array into two sub-arrays of equal size. With these assumptions the number of comparisons made by the sequential algorithm can be determined by solving the following recurrence relation:

The solution to this recurrence relation is:

The parallel algorithm has two phases. First, there are more processes to be sorted than arrays. For example, when the algorithm begins execution, there is only one unsorted array. This iteration then requires n - 1 time units to perform n - 1 comparisons. If we assume p > 2 two processes can partition the two resulting sub-arrays in

time units performing n - 3 comparisons. Similarly, if p > 4 the third iteration requires time at least

to perform n - 7 comparisons. For the first log p iterations there are at least as many processes as partitions and the time required by this phase of the parallel quicksort algorithm is

The number of comparisons performed is

In the second phase of the parallel algorithm there are more sub-arrays to be sorted than processes. All the processes are active. If we assume that every process performs an equal share of the comparisons then the time required is simply the number of comparisons performed divided by p. Hence


The estimated speedup achievable by the parallel quicksort algorithm is the sequential time divided by the parallel time:

Table 1 and figure 1 show predicted speedup of parallel sorting algorithm. For example the best speedup we could expect with n = 1,000,000 and p = 16 is approximately 6.53. Why is speedup so low? The problem with quicksort is its divide-and-conquer nature. Until the first sub-array is partitioned there are no more partitioning to do. Even after the first partitioning step is complete there are only two sub-arrays to work with. Hence many processes are idle at the beginning of the parallel algorithms execution waiting for work.

In this section we proposed a scheme of a parallel sorting algorithm, which is based on the well-known master/slave paradigm.
Master partitions an unsorted data sequence into many fractions and sends them to slaves. When the processing at each slave is completed, partial solutions are gathered to construct the sorted data sequence. The time complexity is defined as a sum of times:
Consider the problem of sorting n elements equally distributed among p processors. Our idea is to find a set of p - 1 splitters to part an array with the n elements. Each of elements in the i-th group is less than or equal to each of elements in the (i+1)-th group. The efficiency of this algorithm obviously depends on how evenly the input is split, and this term depends on how well the splitters are chosen.
Figure 2 shows the idea of our algorithm. First the unsorted data array is divided into smaller parts by using splitters. Then those smaller parts are sent to the slaves, which sort them using the quicksort function.
By using splitters it is assured that all the elements left to the splitter element are less or equal to splitter value and all the elements right to the splitter are greater than the splitter value. By doing this, the time consuming merge process is avoided. To make the splitter satisfactory the Median5 function (median value of five elements) is used.The partitioning process that divides an array into smaller parts is described as follows.
First splitter value d1 satisfies 0 < d_1 < n. Equation (11) shows the second step of an array partitioning. There are two possibilities, the value d2 can be greater or less than value d1.

To simplify the analysis, we sort values d1 and d2.
Assume that we already have p - 1 splitter values. The values of splitters d1, d2, ..., dp - 1 are between 0 and n. After sorting splitter values, we introduce new values r1, r2, ..., rp - 1 (sizes of small parts of an array):



The new value dp lies on the interval where
the corresponding value ri : i
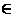 1, ..., p - 1 is maximal. For example, if the value
r2 is maximal, then dp
satisfies d1 < r2 < d2
. The value dp is computed by
Median5 function. Three elements are chosen on indexes
a = di + 1, b = di + 1 - 1
, c = (a + b)/2, if it is assumed that the value
riis maximal. Two elements are chosen randomly
between indexes a and b.
1, ..., p - 1 is maximal. For example, if the value
r2 is maximal, then dp
satisfies d1 < r2 < d2
. The value dp is computed by
Median5 function. Three elements are chosen on indexes
a = di + 1, b = di + 1 - 1
, c = (a + b)/2, if it is assumed that the value
riis maximal. Two elements are chosen randomly
between indexes a and b.
The divide function is similar to the function used by the quicksort algorithm. After calling Divide function the greatest sub-array is divided into two halves. Again, the largest part of the array is chosen and the new splitter value is computed. The partitioning process is repeated until there is one sub-array for every slave.
MASTER and SLAVE algorithms in pseudo code:
Master algorithm:
begin
divide array into smaller parts using Divide
function (as many as the number of slaves)
accordingly to splitters send parts of an array to
all slaves
receive sorted parts and store them to the same
position as they were sent from
end
Slave algorithm:
beginIn this section experimental results of the implemented sorting algorithm on a parallel computing system are presented.
The parallel algorithm was implemented in the C++ programming language. As an interprocess communication the LAM tool [1, 7] was used. The LAM parallel environment features the Message Passing Interface (MPI) standard. In the experiment, data were randomly generated and 20 independent measurements were performed and in this section we operate with the average values.
For sorting sub-arrays, the quicksort function in the C++ programming language was used. In addition the Median5 function, that is used by the master process to split the array into subtasks, was implemented.

The obtained results using PC cluster (PC machines with 64 or 128 MB of main memory, connected in the local area network using ATM) are shown in Table2. The first column presents the size of the data array. The second column presents the number of PC computers (one process per computer). The type of array elements is integer. The time needed for sorting data by one computer is shown in the fourth column. In the fifth column there is the execution time needed by the PC cluster (execution time of the data splitting only is shown in third column). In the next column speedup factor (Eq. 1) is presented. The last column presents the efficiency (Eq. 3). The speedup values are between 1 and 2.6. In the last part of the table, speedup values are up to 20. In this case computer with 128 MB of main memory began swapping during quicksort execution.
The graphs on the figures 3, 4, and 5 show execution times using PC cluster to sort 1, 5, 10, 15, 20, 25 millions of data elements, respectively. As it is evident, the times almost do not differ when small arrays are used. But when larger arrays are being sorted, the differences are more apparent.
The experimental results show that the PC cluster approach can be profitably used, when the size of the problem is sufficiently large (so that parallel computing is required).



In this paper the theoretical aspects of the speedup of a parallel sorting strategy and the sorting algorithm on a PC cluster and experimental study of its performance were presented. The obtained results show that a large data set is sorted faster if there is a PC cluster rather than only one computer used.
In the future we want to parallelize the first phase of our sorting algorithm and increase the number of machines in the PC cluster.
[1] Gregory D. Burns, Raja B. Daoud, and James R. Vaigl. An Open Cluster Environment for MPI. In Supercomputing Symposium '94, Toronto, Canada, June 1994.
[2] Ralf Diekmann, Joern Gehring, Reinhard Lueling, Burkhard Monien, Markus Nuebel, and Rolf Wanka. Sorting large data sets on a massively parallel system. In Proc. 6th IEEE-SPDP, pages 2--9, 1994.
[3] Mary M. Eshagian, editor. Heterogeneous Computing. Artech House, Inc., Norwood, MA 02062, ISBN 0-89006-552-7, 1996.
[4] Fix and Ladner. Sorting by parallel insertion on a one-dimensional subbus array. IEEETC: IEEE Transactions on Computers, 47, 1998.
[5] J. D. Fix and R. E. Ladner. Sorting by parallel insertion on a one-dimensional sub-bus array. Technical Report TR-96-09-02, University of Washington, Department of Computer Science and Engineering, September 1996.
[6] Debasish Ghose and Hyoung Joong Kim. Load partitioning and trade-off study for large matrix-vector computations in multicast bus networks with communication delays. Journal of Parallel and Distributed Computing, 55(1):32-59, 25 November 1998.
[7] Gregory D. Burns, Vibha S. Dixit, Raja B. Daoud, and Raghu K. Machiraju. All About Trollius. Occam users group newletter, August, 1990.
[8] Helman and JaJa. Sorting on clusters of SMPs. INFRMTCA: Informatica: An International Journal of Computing and Informatics, 23:113-121, 1999.
[9] David R. Helman, David A. Bader, and Joseph JaJa. A randomized parallel sorting algorithm with an experimental study. Journal of Parallel and Distributed Computing, 52(1):1-23, 10 July 1998.
[10] Debra Hensgen, editor. Proceedings: Sixth Heterogeneous Computing Workshop (HCW'97). IEEE Computer Society Press, Los Alamitos, CA, April 1997.
[11] F. T. Leighton. Introduction to Parallel Architectures: Arrays, Trees, Hypercubes. Morgan Kaufmann Publishers, 1992.
[12] W. M. Lin and W. Xie. Minimizing Communication Conflicts with Load-Skewing Task Assignment Techniques on Network of Workstations. INFRMTCA: Informatica: An International Journal of Computing and Informatics, 23:57-66, 1999.
[13] Udi Manber. Introduction to Algorithms, a Creative Approach. Addison-Wesley Publishing Company Inc., 1989.
[14] Min Tan, Howard Jay Siegel, John K. Antonio and Yan Alexander Li. Minimizing the Application Execution time Through Schudeling of Subtasks and Communication Traffic in a Heterogeneous Computing System. IEEE Transaction on Parallel and Distributed Systems, Vol. 8(No. 8):173-186, August, 1997.
[15] M. Quinn. Parallel Computing: Theory and Practice. McGraw-Hill, 1994.
[16] V. Zumer, M. Ojstersek, A. Vreze, and J. Brest. Sorting on Heterogeneous Computing System. In MIPRO'99: 10-th International Conference on Computers in Inteligent Systems, volume 2, pages 1-4, Opatia, Croatia, 1999.
[17] Barry Wilkinson and Michael Allen. Parallel Programming: Techniques and Applications Using Networked Workstations and Parallel Computers . Prentice-Hall, Englewood Cliffs, NJ 07632, USA, 1998.