XML Dataspaces for Mobile Agent Coordination
Giacomo
Cabri, Letizia Leonardi, Franco Zambonelli
Dipartimento
di Scienze dell’Ingegneria – Università di Modena e
Reggio Emilia
Via
Campi 213/b – 41100 Modena – ITALY
E-mail:
{giacomo.cabri, letizia.leonardi, franco.zambonelli}@unimo.it
Abstract
This paper presents MARS X, a programmable coordination architecture for Internet applications based on mobile agents. In MARS X, derived from the MARS coordination architecture, agents coordinate through programmable XML dataspaces, accessed by agents in a Linda-like fashion. This suits very well the characteristics of the Internet environment, because MARS X enforces open and uncoupled interactions and offers all the advantages of XML in terms of standard interoperability. In addition, coordination in MARS X is made more flexible and secure by the capability of programming the behaviour of the XML dataspaces in reaction to the agents' accesses. An application example related to the management of on-line academic courses shows the suitability and the effectiveness of the MARS X architecture.
Developing distributed applications in the Internet raises several problems, due to the intrinsic characteristics of the Internet itself. First, decentralised management and openness make the Internet populated by a multitude of heterogeneous entities (services and information sources) with which application components may be in need to interact, thus raising interoperability problems. Second, the intrinsic dynamicity of the scenario and the unreliability of Internet connections require suitable programming paradigms and coordination technologies, to facilitate the design and the execution of Internet applications.
With regard to interoperability, the incredible success of HTML has recently led the WWW consortium to the development of XML [19], a language for data representation which is likely to become a standard for interoperability in the Internet, due to the advantages in can provide in this context. In fact, XML represents data in a familiar (HTML-like) tagged textual form, and explicitly separates the treatment of data from its representation. This achieves the platform-independence required for the Internet and the well-appreciated feature of human-readability. In addition, XML can be made capable of representing whatever kind of data and entity one is likely to find in the Internet: complex documents, service interfaces and objects, communication protocols, as well as agents. These characteristics let us think that interoperability in the Internet will be information-oriented and based on XML, rather than service-oriented and based on CORBA [14].
With regard to programming paradigms and coordination technologies for Internet applications, the most suitable solutions seem to be represented by mobile agents and Linda-like tuple spaces, respectively. On the one hand, a programming paradigm based on active and autonomous software entities that can dynamically plan their execution activities, thereby included the capability of transferring their execution across different execution environments (i.e., Internet sites), suits well Internet applications. In fact, agents can help application designers in dealing with the intrinsic uncertainty that they can have about the target environment, as well as with the intrinsic dynamicity and unreliability of Internet sites and their connections [8, 12]. On the other hand, whenever mobility and dynamicity are involved, coordination models that force a strict coupling between the interacting entities (such as peer-to-peer and client-server ones) force odd design choices in applications and lead to inefficiency in execution. Therefore, we argue that fully uncoupled coordination models based on the tuple space concept [2, 16], adopted for both inter-agent coordination and for making agents interact with their current execution environment, suits Internet applications based on mobile agents and leads to simpler application design [4].
Putting all together, we have designed and implemented MARS X as an extension of the MARS coordination architecture for mobile agents, previously developed by the authors [3]. In particular, MARS X exploits the advantages of a programmable Linda-like coordination model [7], implemented by MARS, by enriching it with the capability of exploiting XML in the context of a more general Internet architecture based on XML. In MARS X, agents coordinate – both with each other and with their current execution environment – through programmable XML dataspaces associated to each execution environment and accessed by agents in a Linda-like fashion, as if they were tuple spaces. This can provide several advantages in mobile agent applications, combining a high-degree of interoperability with a high-degree of interaction uncoupling. In addition, since the behaviour of the XML dataspaces in response of the agent accesses can be fully programmed, MARS X enables both environment- and application-specific coordination laws to be embedded in a dataspace, thus providing for a more secure and flexible coordination mean. An application example in the area of agent-mediated management of on-line academic courses is assumed as a case study to show the effectiveness of the MARS X approach.
The paper is organised as follows. Section 2 discusses the issues arising in the adoption of XML as a base for interoperability, and proposes an Internet architecture based on XML. Section 3 presents the MARS X architecture. Section 4 presents the application example. Section 5 discusses related work. Section 6 concludes the paper.
XML is a promising technology to achieve interoperability in the Internet world. However, one should ask what architecture could be conceived to allow heterogeneous components to interoperate via XML.
Currently, the most natural and intuitive way to exploit XML is in the Web, as a data representation format more flexible and powerful than HTML. In XML, like in HTML, data is recorded in a standard, textual, format that can be read and manipulated by several kinds of application. However, in HTML, tags explicitly commit applications to a specific use (i.e., a specific visualisation format) of the enclosed information. Instead, in XML, it is up to the application level to decide what to do (i.e., how to elaborate and visualise) enclosed information. Therefore, in the context of Web servers, XML enables a more modular approach to servers' design. The server administrator can store its information in XML, adopting the most natural format for its data, and disregarding any issue related to data visualisation. In addition, information can be retrieved from a legacy DBMS and translated to a XML format. At a higher level, the XML-coded information can be translated into HTML pages to be visualised by a standard HTML browser, on the basis of specific XSL visualisation information [20]. In addition, the information level can store XML information related to server management, to be read and interpreted by the server during its activities, as it is for example defined by the Channel Definition Format [5], and exploited by Microsoft Active Channels.
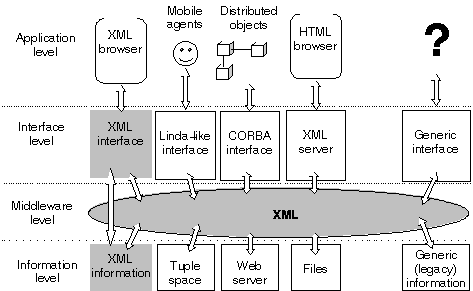
Exploiting XML in the Web naturally leads to a multi-layered architecture (see figure 1). At the application level, the browser must be allowed to elaborate information in HTML format. An XML server must be provided at the interface level for interfacing the browser with the XML dataspace. The XML dataspace acts as a middleware level for the data stored in a DBMS at the lowest information level. Whenever the information on a site is not already stored in XML format (in which case the middleware and the information level collapse in a single level), data is translated from/to the information level up to the middleware level.
The identified four-level architecture may be considered as a more general architecture for Internet applications (see Figure 2). In the information level, we can take into account the presence of any kind of data stored in whatever kind of format: bare files, tuples in a tuple space, objects, service interfaces. Provided that all this data can be represented in XML, the middleware level can furnish the necessary tool to transform this data in XML format and viceversa, and store (or dynamically produce) them into the XML dataspace. It is expected that the emergence of XML as a standard will make these kinds of tools widely available. The interface level is in charge of publishing the information in the formats requested by the different application components and/or according to specific protocol/coordination models. Different components may be present at this level, depending on the variety of different application components that may be in need of accessing the XML dataspace. Components may include XML browsers, CORBA interfaces and applications to interact with the XML dataspaces, Linda-like interfaces for enabling mobile agent coordination. It is expected that the increasing diffusion of XML will also increase the capability of application components to directly read and elaborate on XML dataspaces, thus making it unnecessary any translation of data from XML to a specific application level format. Nevertheless, the interface level will maintain its role of implementing specific consistency and control policies for the accesses to the data.
The above-described architecture is very general and presents several advantages in terms of interoperability, dynamicity and component scalability. In the following, we restrict our focus to mobile agents applications, and on the provision of a Linda-like interface to mobile agents.
Figure 1. An XML architecture for the Web
Figure 2. A general XML architecture
In mobile agent applications, the adoption of a Linda-like coordination model is the most suitable solution for both inter-agent and agent-to-execution environment coordination [4, 15]. In the context of the general XML architecture described in the previous section, accommodating a Linda-like coordination style for mobile agents amounts at: (i) integrating specific architectural solutions tuned to mobile agent applications; (ii) providing a Linda-like interface for enabling agent access to XML dataspaces; (iii) enabling the association of specific computational activities to the accesses performed by agents, thus defining a programmable tuple space model.
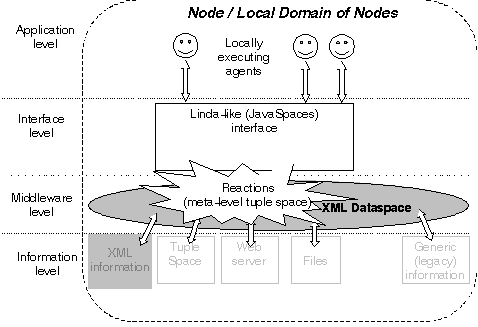
In this section, we describe the MARS X coordination architecture for mobile agents (see Figure 3), which is an extension to the MARS coordination architecture [3]. We show how the above issues have found appropriate solutions, via: (i) an architecture which enforces locality in the accesses; (ii) the implementation of the standard JavaSpaces interface and (iii) a simple yet effective programmable tuple space model based on meta-level tuple spaces.
As a general note, we emphasise that MARS X does not implement a whole new Java agent system. Instead, it has been designed to complement the functionality of already available agent systems, and it is not bound to any specific implementation: it can be associated to different Java-based mobile agent systems with only a slight extension. In addition, we feel it should not be difficult to adapt the current implementation in order to allow different application-level entities, apart from mobile agents, to exploit MARS X for the coordination of their activities.
Figure 3. The MARS X architecture
Since mobile agents travel the network in the effort of enforcing locality in the access to the needed resources, the architecture needs to somehow facilitate the agents' efforts. To this end, a coordination architecture for mobile agents must provide a multiplicity of independent tuple spaces, to be accessed by agents either in a strictly local way or in a network-aware fashion. This implies that XML dataspaces have to be considered local resources associated to a node.
MARS X strictly enforces the concept of locality in interactions. An Internet node must define its own XML dataspace and the associated Linda-like interface. In addition, a domain of nodes (e.g., a local network) can federate and implement a single XML dataspace. When an agent arrives on a node it is automatically provided with a reference to the local MARS X tuple space interface associated to that node. Then, it can use this reference to access the local XML dataspace in a Linda-like fashion, i.e., by reading, extracting, inserting fragments of XML data into the dataspace, as if they were tuples. In the case of agents executing in a domain, they can access the XML dataspace transparently from anywhere in the domain.
Since the current architecture forces an agent to migrate to a node to access to its local dataspace, we are planning to extend the architecture by providing the possibility for agents to access a given XML dataspace from remote in a network-aware way (for example, by identifying it via a URL, as in TuCSoN [15]). This will allow non-mobile distributed agents to interact via a remote dataspace.
MARS X adopts the MARS interface (see Figure 4), which is, in its turn, JavaSpaces compliant [11]. This choice has been driven by both the simplicity of the JavaSpaces interface and by its widespread diffusion. However, it would have been also possible to adopt a different interface, e.g., the T Spaces one [10].
A MARS X tuple space assumes the form of a Java object making available the following three operations for accessing the tuple space:
read, which retrieves a tuple matching a given template;
take, which extracts the matching tuple from the tuple space;
write, which puts a tuple in the tuple space.
Two additional operations, readAll and takeAll, not present in the JavaSpaces interface, have been added to the MARS interface to avoid agents being forced to perform several reads/takes to retrieve all the needed information, with the risk of retrieving the same tuples several times. This is a well-known problem of tuple space model, due to the non-determinism in the selection of a tuple among multiple matching ones.
public interface MARS
extends JavaSpace
{// interface methods
inherited from JavaSpace
// put a tuple into the
space
// Lease write(Entry e,
Transaction txn, long lease);
// read a matching tuple
from the space
// Entry read(Entry
tmpl, Transaction txn, long timeout);
// extract a matching
tuple from the space
// Entry take(Entry
tmpl, Transaction txn, long timeout);
// interface methods
added by MARS
// read all matching
tuples
Vector readAll(Entry
tmpl, Transaction txn, long timeout);
// extract all matching
tuples
Vector takeAll(Entry
tmpl, Transaction txn, long timeout);
}
Figure 4. The MARS X interface
The txn parameter can specify a transaction the operation belongs to. The timeout parameter of read, take, readAll and takeAll, specifies the time to wait before the operation returns a null value if no matching tuple is found: while NO_WAIT means to return immediately, 0 means to wait indefinitely. The lease parameter of the write operation sets the lifetime of the written tuple.
Our choice of implementing JavaSpaces interface rather than defining a new "XML-oriented" Linda-like interface, has been mainly driven by the fact that the JavaSpaces technology is likely to have a great impact in the context of distributed Java applications. Furthermore, we think that the JavaSpaces choice better suits the object-orientation of Java agents, by making them manage object tuples rather than XML fragments. In fact, from the agents’ point of view, MARS X tuples are Java objects whose instance variables represent the tuple fields. The interface operations are in charge of translating the object representation of tuples to the corresponding XML representation (write operation) and viceversa (read, take, readAll, takeAll operations), as well as of handling the insertion/removal of tuples from the documents of the XML dataspace. This also includes the translation in a textual form of non-string fields, such as Integer and Float ones.
In MARS X, tuple management requires that tuple classes implement the Entry interface. The easiest way to do this is to derive a tuple class from the AbstractEntry class (that defines the basic tuple properties by implementing the Entry interface) and to define, as instance variables, the specific tuple fields. Each field of the tuple is a reference to an object that can also represent primitive data type (wrapper objects in the Java terminology). In addition, in MARS X, a tuple class must have a static private field that specifies a DTD that describes the structure of the XML documents corresponding to the instances of such class. In fact, in MARS X the DTDs correspond to the tuple classes, as well as the XML documents correspond to the tuple objects. An example of tuple class is shown in figure 5, while figure 6 shows how an agent can use this class to access the XML dataspace.
class _infoN extends
AbstractEntry { // AbstractEntry: generic tuple
//class field
static private final
URL DTDfile = new URL(“http://mysite/myDTD.dtd”);
// tuple fields
public Integer f1;
public String f2;
public String f3;
public Integer f4;
}
Figure 5. Example of tuple class
...
_infoN t = new _infoN();
t.f2 = “foo”;
t.f3 = “*bl*”;
t.f4 = 17;
myEntry result =
space.read(t, new Transaction(null), NO_WAIT);
...
Figure 6. Fragment of code of an agent
A tuple corresponds to an element of an XML document. In particular:
the name of the class, which must begin with the underscore character, corresponds, once deleted the initial underscore, to the name of the tag defining the XML element;
the names of instance variables correspond, orderly, to the name of the tags enclosed in the XML element;
the values of the instance variables correspond, orderly, to the data enclosed in the corresponding tags.
Names of classes and instance variables can be dynamically acquired via Java reflection. For example, the _infoN tuple class defined in figure 5, corresponds to an <infoN>…</infoN> element in the XML document of figure 7.
<?XML version="1.0"?>
<!DOCTYPE myEntry
SYSTEM “http://mysite/myDTD.dtd”>
<infoN>
<f1>3</f1>
<f2>foo</f2>
<f3>blahblah</f3>
<f4>17</f4>
</infoN>
<infoN>
<f1>5</f1>
<f2>foo2</f2>
<f3>bar</f3>
<f4>23</f4>
</infoN>
Figure 7. Tuples as XML elements
The pattern matching currently implemented in MARS X uses a textual comparison between the XML elements. A template tuple in an input operation can contain formal values (i.e., not defined), which can match with any value in the corresponding XML element, and actual values (i.e., with a well-defined value). In the case of string fields, partially defined values can be expressed by exploiting wild cards ("*" and "?" only, in the current implementation). When an input operation is invoked by an agent, MARS X performs a search in the XML dataspace, to find one element in a XML document such that:
the DTD used by the document is the one specified in the static private field of the template tuple;
the tuple translated in XML format corresponds to at least one element in the document
the values of the defined (or partially defined) fields in the tuple correspond to the values in the tags of the element.
Figure 7 shows (on grey) the fragment of an XML document that can be returned, in the form of a tuple, by the read operation requested in figure 6. The agent initialises the fields f2, f3 and f4, maintaining f1 as formal. Match occurs because the values of the fields f2 and f4 are the same of those specified in the template tuple by the agent, and because the value of the field f3 matches the regular expression in the field f3 of the tuple. In addition, the value 3 is assigned to the field f1. The same XML fragment would have been extracted from the document if the agent had performed a take operation with the same template tuple.
The current implementation of the MARS X interface, although operative, still suffers of some limitations, which are being addressed at the time of writing. First, the interface still lacks the capacity of managing in an appropriate way all of the components and structures that can be found in XML documents. In particular: (i) the current implementation considers the attributes of a tag as additional tags, thus lacking in realising a perfect one-to-one correspondence between XML elements and tuple objects; (ii) the implementation does not handle XML namespaces, necessary to avoid conflicts in the tags' names and, therefore, to correctly implement the pattern-matching mechanism. Second, synchronisation of concurrent accesses is based on a MR/SW (Multiple Readers/Single Writers) policy applied at the level of single XML documents. This choice promotes simplicity and also allows any other application-level entity to access an XML dataspace in concurrency with mobile agents, provided that it conforms to the same policy. However, the MR/SW policy at the level of single documents may not be the most appropriate choice when multiple agents are in need of performing complex transactions over different documents, or when multiple agents are in need of performing concurrent operations on different parts of the same XML documents. Therefore, we are currently evaluating whether different synchronisation policies can be conceived and can coexist with the MR/SW in a XML dataspace. A third direction of improvement relates to security control. Currently, the mechanisms for controlling the accesses to the XML dataspace are based on Access Control Lists associated to each XML document, to specify which agents can read, write, or extract elements (i.e., tuples) from the document. This kind of access control may have coarse granularity when mobile agents are in need of working at the level of single tuples, too.
The behaviour of MARS X can be programmed, both by administrators and by mobile agents, via the installation of reactions associated to specific access events, which are triggered when the corresponding events occur. Such reactions can modify the result of the operations they are associated with, can manipulate the content of the XML dataspace, and can access whatever kind of external entity they are in need of accessing.
The introduction of a programmable tuple space model (whether based on XML dataspaces or not) provides for much greater flexibility and control in interactions than the raw Linda model [4, 15]. A site administrator can program reactions to monitor the access events to the local resources and, in need, to issue specific actions to preserve its resources from malicious accesses. Reactions can be used to implement a dynamic dataspace model, in which the data is not statically stored in the dataspace but, instead, is dynamically produced on-demand and is possibly originated from different sources. In the context of XML dataspaces, and with reference to the general XML architecture sketched in section 2, reactions can thus act as a bridge between the information level and the XML middleware level (see Figure 3). Dynamic production of tuples also enables a simple data-oriented way of accessing services on a site: the attempt to read a specific tuple by an agent can trigger the execution of a local service, in charge of producing the required tuple as a result. In this direction, reactions can be used to establish and control session-based communications between agents. Consequently, in the context of XML dataspaces, which are likely to be accessed by entities other than mobile agents, we also envision the possibility of exploiting reactions to control the interactions between entities that are heterogeneous in terms of supported coordination models.
Further advantages could be provided by giving application agents the capability of defining their own coordination rules: agents can carry along the code of the reactions implementing application-specific coordination policies, and install them in the tuple spaces of the sites visited. This achieves a sharp separation of concerns between algorithmic and coordination issues [9]: the agents are in charge of embodying the algorithms to solve the problems; the reactions represent the application-specific coordination rules. This can both reduce the agent complexity and simplify the global application design [4].
In the implementation of a programmable tuple space model, MARS X exploit the implementation of the MARS reactive model [3]. Reactions are stateful objects with a method (named "reaction") whose code represents the core of the reaction, and are associated to specific access events on the basis of the three components that characterise the access event: tuple item (T), operation type (O) and agent identity (I). Therefore, the association of a reaction to an access event is then represented via a 4-ple (Rct, T, O, I): the reaction method of the object Rct (i.e., the reaction itself) is executed when an agent with identity I invokes the operation O on a tuple matching T. In this perspective, the association of reactions to tuples can be considered as dealt with meta-level tuples enclosed in a meta-level tuple space, which has to follow associative mechanisms similar to the one of the base-level tuple space. Putting and extracting tuples from the meta-level tuple space provide installing and de-installing reactions. A meta-level 4-ple (possibly with some non-defined values) associates the reaction to all the accesses that matches that 4-ple. A match in the meta-level triggers the corresponding reaction. For example, a meta-level 4-ple (ReactionObj, null, read, null) associates the reaction of ReactionObj to all read operations, disregarding both the peculiar tuple content and the agent identity. Analogously, one can associate reactions to a specific tuple, to all tuples, or to the tuples of a given class. The pattern-matching mechanism in the meta-level tuple space is activated for any access to the “base-level” tuple space to check for the presence of reactions to be executed.
The reaction method has to be defined according to the following prototype:
public Entry reaction(MARS X s, Entry Et, Operation O, Identity I)
The parameters represent, orderly: the reference to the local MARS X space, the reference to the tuple resulting from the matching mechanism issued by the associated operation, the operation itself, and the identity of the invoking agent. The code of the reaction has access to the base-level tuple space and to the meta-level one and can perform any kind of operation on them (tuple space access operations performed within the code of a reaction do not issue any reaction, to avoid endless recursions). As a consequence, the behaviour of the reaction can depend both on the actual content of the tuple space and on past access events. Also, having the availability of the result of the matching mechanism and of the associated operation, the reaction can also influence the semantics of operations and, for example, can return to invoking agents different tuples than the ones resulting from the stateless and less flexible, Linda-like matching mechanisms.
The current security mechanisms defined for the meta-level tuple space are, again, based on Access Control Lists, to specify which agents have the rights to install which kinds of reactions in an XML dataspace. For instance, an administrator agent may be allowed to install whatever kind of reaction; a generic application agent can only install reactions to be triggered by other agents of the same applications. Also in this case, we feel that the above security model is too coarse-grained to satisfy the needs of both administrators and application agents, and its refinement is an in-progress work direction. As another limitation, the current implementation of the MARS X reactive model, which fully re-use the MARS implementation [3], does not realise the meta-level tuple space as an XML dataspace. Instead, it stores meta-level tuples in an object form and, consequently, requires the meta-level pattern-matching mechanisms to occur with application level tuples in their object form, too. It is our intention to upgrade the implementation of the meta-level tuple space so as to make it become an XML dataspace in its turn.
In this section, we apply MARS X in the context of the management of on-line university courses.
Let us suppose different universities and academic departments federate to make the material of the courses available on-line, to allow both students to easily retrieve material of interest and teachers to easily upgrade it. To this end, they can agree on adopting XML as a standard data representation format for course material, and adopt a well-defined DTD for the corresponding XML documents. Figure 8 shows a sample of XML document containing information related to a course. This includes general information about the course, as well as specific information for each of the lessons of the course, such as abstract and suggested readings.
With reference to the general architecture described in section 2, the XML representation of course material defines an XML dataspace that could either derive from a translation of previously available material stored at the information level in a different format, or be written from scratch in XML if no material were previously available. In addition, this material could be made available to application clients in different ways, i.e., by adopting different interfaces.
<?XML version="1.0"?>
<!DOCTYPE CourseEntry
SYSTEM “http://univ.site/UnivCourse.dtd ”>
<course>
<coursename>Computer
Networks</coursename>
<year>4</year>
<semester>1</semester>
<teacher>Jane
Smith</teacher>
<lesson>
<lessonname>Introduction</lessonname>
<lessonnumber>1</lessonnumber>
<abstract>blah
blah</abstract>
<reading>
<authors>..</authors>
<title>…</title>
<book>…</book>
…
</reading>
<reading>…</reading>
</lesson>
<lesson>
…
</lesson>
…
</course>
Figure 8. Example of an XML document describing a course
class _course extends
AbstractEntry {
static private URL
DTDfile = new URL(“http://university.site/UnivCourse.dtd”);
public String
coursename; // the name of the course
public Integer year;
// when it is scheduled: year
public Integer
semester; // and semester
public String
Teacher; // the teacher of the course
public _lesson lesson[
]; // lessons that compose the course }
class _lesson extends
AbstractEntry {
static private URL
DTDfile = new URL(“http://university.site/UnivCourse.dtd”);
public String
lessonname; // the name of the lesson
public Integer
lessonnumber; // the number of the lesson
public String
abstract; // the abstract of the lesson
public _reading
reading[ ]; // suggested readings
class _reading extends
AbstractEntry {
static private URL
DTDfile = new URL(“http://university.site/UnivCourse.dtd”);
public String authors[
]; // authors of the reading
public String title;
// title of the reading
public String Book; //
where it is published:
public Integer
volume; // volume
public Integer
number; // and number }
Figure 9. MARS X tuples corresponding to course, lesson, reading elements.
As a first, simple, example related to information retrieval, let us consider a student that wants to acquire information related to a course or to a specific lesson. If the academic federation makes available XML servers on their sites, (s)he can simply use a browser to navigate trough the XML dataspaces of the federation and analyse their content. However, this search activities can be rather time expensive and boring if the federation is a large one and the course material detailed and verbose. Therefore, if the federation sites can host mobile agents and make the MARS X interface available, students can decide to delegate the search activities to mobile agents. To this end, the agent must define (or have the availability of) the tuple classes representing the XML elements of interest. Figure 9 reports the definition of the tuple classes representing the XML elements <course>, <lesson> and <reading>. Then, the agent can exploit the operations of the MARS X interface to retrieve the needed information in a simple and effective way. Figure 10 reports a simple code fragment of an agent that travels across the sites of the federation to retrieve information about those lessons containing the keyword "network" in the abstract.
_lesson lesson; // found
lesson
...
_lesson tmplesson = new
_lesson(); // template lesson
tmplesson.abstract =
"*networks*" // partially defined field
for(i=0; i<
sites_of_the_federation.length;i++) // for all federation sites
{
go(sites_of_the_federation[i]); // go to the current site in the
list
if ((lesson =
S.read(tmplesson, new Transaction(null), NO_WAIT)) != null)
// if a lesson
containing "network" in the abstract is found
go(home); // go
back home
}
...
Figure 10. Code fragment of an agent searching for a specific lesson
_course updatecourse;
...
_course templatecourse =
new _course();
templatecourse.teacher =
"Jane Smith" // defined field
for(i=0; i<
sites_of_the_federation.length;i++) // for all the sites
in the federation
{
go(sites_of_the_federation[i]); // go to the current site in the
list
if ((updatecourse =
S.take(templatecourse, new Transaction(null), NO_WAIT)) != null)
{ if(updatecourse.semester == 1) updatecourse.semester = 2;
else
updatecourse.semester = 1;
S.write(updatecourse, new Transaction(null), 0); }
}
go(home); // go back
home
}
...
Figure 11. Code fragment of an agent in charge of updating semester information
Another example relates to information management. Let us consider that professor Jane Smith wants to update the information about the courses she is the teacher of. For example, let us suppose that she wants to exchange the semester during which her courses are held. To this end, she can employ an agent that travels across the sites of the federation (or just across a few known sites storing information about her courses), extracts the information about a course and writes it again with the updated semester indication. Figure 11 shows a simple code fragment of agent performing this task. Of course, to perform its task, the agent launched by Jane Smith must be allowed to extract and write tuples from the XML documents containing information about her courses. However, it must not be allowed to extract and modify information about courses held by other teachers. To this end, since Access Control Lists in MARS X apply at the level of single documents, security reasons require each course to be stored in a different XML document, thus forcing each site to adopt a specific file organisation for the XML dataspace. This clarifies why we consider the current Access Control Lists approach of MARS X inadequate.
In both the above examples, although very simple, MARS X programmability can provide advantages. With regard to the first example, a site can decide to associate a reaction to any read operation performed on its dataspace, with the goal of monitoring the activities on the dataspace and maintaining a log file. The code for this simple reaction is shown is figure 12 and it can be associated to any read event by writing the meta-level tuple (MonitorObj, read, null, null) in the meta-level tuple space (MonitorObj has to be an instance of the Monitor reaction class).
class Monitor implements
Reactivity
{ public Entry
reaction(MARS X s, Entry Fe, Operation Op, Identity Id)
{
SecurityRegister.add(“read”, Fe, Id); // log the access
return Fe } //
returns the matching tuple to the invoking agent}
Figure 12. The Monitor reaction class
class PreventTake
implements Reactivity
{ public Entry
reaction(MARS X s, Entry Fe, Operation Op, Identity Id)
{ UpdateTuple ut = new
UpdateTuple(); // create the update record
// information about
the deleted tuple
Fe = s.read(Fe, new
Transaction(null), NO_WAIT);
ut.coursename =
((_course)Fe).coursename;
ut.tuple = Fe;
s.write(ut, new
Transaction(null), 0); // store the update record
return Fe; }} //
returns matching tuple without deleting it
class RightUpdate
implements Reactivity
{ public Entry
reaction(MARS X s, Entry Fe, Operation Op, Identity Id)
{ UpdateTuple ut = new
UpdateTuple();
ut.coursename =
((_course)Fe).coursename;
UpdateTuple
tupleupdated;
// if there is an
update record for the same course
if ((tupleupdated =
s.take(ut, new Transaction(null), NO_WAIT)) != null)
// delete the old
tuple
s.take(ut.tuple, new
Transaction(null), NO_WAIT);
s.write(Fe, new
Transaction(null), 0);
return null; }}
Figure 13. The PreventTake and RightUpdate reaction classes
With regard to the second example, reactions can be associated to both take and write operation in order to preserve the consistency of the information in the dataspace, i.e., to guarantee that the information about a course is deleted from the dataspace only when the updated information is inserted. To this end, a reaction associated to the take operation must return the course tuple without deleting it from the space, and must keep record of the attempted take, for example via an update record that is a tuple stored in the space. The reaction associated with the writing of a new course tuple must check whether such record for the same course tuple exists, and delete the old version from the dataspace. Figure 13 shows the code of the classes that implement such reactions, which can be installed by writing the two meta-level tuples (PreventTakeObj, take, new _course(), null) and (RightUpdateObj, write, new _course(), null) in the meta-level tuple space. By specifying the agent identities in the fourth field in the meta-level tuples, one can also discriminate which classes of agents must trigger the reactions and which must not. For instance, there may be the need of letting specific “administrator agents” perform take operations on course tuples without having to insert updated tuples. One could criticise that the collective behaviour of the PreventTake and RightUpdate reactions can be easily implemented by making use of the JavaSpaces’ transaction mechanism. However, JavaSpaces’ transactions require an agent-level identification of the problem. In MARS X, instead, the agent can disregard the problem, because the consistency of the XML dataspace is ensured from the internal, through a proper programming of its behaviour.
The above examples show how MARS X can be used for co-ordination between agents and execution environment. Of course, MARS-X can be also exploited for coordination among agents.
While several mobile agent systems have been proposed in the last few years, and new ones keep on appearing, only a few of them focus on the definition of appropriate coordination models and/or on the adoption of XML as a language for agent interactions.
The PageSpace coordination architecture for interactive Web applications exploits Linda-like coordination [6]: a multitude of tuple spaces in different execution environments can be used by agents to coordinate with each other. However, unlike MARS X, PageSpace neither defines a programmable coordination model nor specifically focuses on the problem of standardising data representation toward interoperability. With regard to the latter problem, a foreign entity can be enabled to interoperate with a PageSpace application only by "agentifying" it, i.e., by associating it with a special-purpose PageSpace agent.
The LIME coordination model addresses in a unifying model both logical and physical mobility [17]. Each mobile entity – whether an agent or a physical device – has associated an Interface Tuple Space (ITS), which can be seen as a personal tuple space where to store and retrieve tuples. When mobile entities meet in the same physical place, their ITSs automatically merged, thus allowing Linda-like coordination between mobile entities via temporarily shared tuple spaces. LIME also provides for programmability of tuple spaces, although in a form more limited than the MARS X one: a mobile entity can program the behaviour of its own ITS only, in order to provide better control over the accesses to it. As a final note, being an abstract model rather than a concrete implementation, LIME currently neglects interoperability problems, such as data representation.
The TuCSoN model [15], developed in the context of an affiliated research project, defines a programmable coordination model based on logic tuple spaces, associated with the execution environments and to be used for the coordination of knowledge-oriented mobile agents. Logic tuple spaces define a Linda-like interface, while reactions are programmed as first-order logic tuples. The exploitation of logic programming in reactions complements the object-oriented MARS X reaction model and makes TuCSoN very well suited to the distributed management of large information systems. However, although the untyping of data of the logic model somehow facilitates interoperability (and it would also facilitate translation of logic tuples into an XML format), interoperability problems have to be solved in TuCSoN by explicitly programming "translator" reactions.
The T Spaces project at IBM [10] defines Linda-like interaction spaces to be used as general-purpose information repositories for networked and mobile applications. T Spaces recognises the limits of the basic Linda model and integrates a peculiar form of programmability, by enabling the addition of new operations on a tuple space. This makes T Spaces not very usable in the open Internet environment, since it requires application agents to be aware of the operations available in a given tuple space. With regard to interoperability, a project related to T Spaces and described in [1] reports one of the few efforts towards the integration of XML and Linda technologies. The goal is to enable T Spaces to accept XML documents and store them as tuples in the tuple space. Incoming XML documents are processed to produce a DOM tree whose nodes are stored as T Spaces tuples, while tuples representing fragments of an XML file can be extracted to reconstruct the original XML document. This approach is somewhat dual of the MARS X one, where JavaSpaces tuples are translated for storing as fragments of an XML file and, viceversa, fragments of an XML file can be extracted and translated into JavaSpaces tuples. In our opinion, the MARS X approach has to be preferred: to preserve interoperability, it is better to store XML files in their original format, and produce tuples on-demand, when they are needed by some application agents.
Law-Governed Linda (LGL) [13] defines Linda-like tuple spaces in which laws can be defined to control the execution of the original Linda operations. In particular, LGL provides some primitive directives that can be put together to compose laws. The LGL model is particularly useful and effective to control interactions and to enforce security in an open system. However, LGL differs from MARS-X in that laws are intended to constrain the accesses to the tuple space performed by agents, rather than to enrich and modify the semantics of the access events, as it can be done in MARS-X.
The presented MARS X architecture, by exploiting the power and the flexibility of a programmable Linda-like coordination model in the context of XML dataspaces, may provide several advantages in Internet applications. In fact, while programmable Linda-like coordination suits the mobility of the application components and the openness of the Internet scenario, the emergent XML standard for Internet data representation may guarantee a high-degree of interoperability between heterogeneous components.
Apart from the need of updating portions of the current implementation (as discussed in section 3), there are still several issues to be solved to make the MARS X architecture practically usable. These issues mainly relates to the lack of some XML specifications that are instead necessary for any effective management (and consequently for a tuple-based management) of XML documents [18]. The XML schemas specification will permit to better specify data types in XML documents than the current version; this specification, together with the integration of XML namespaces in the current implementation, will be of great help in translating XML fields into Java objects (and viceversa), and in improving the effectiveness of the pattern matching mechanism. The Xpath specification, by defining how to navigate into an XML document and how to identify selected parts of it, will possibly provide better and more efficient ways for querying the XML dataspace. The XML fragments specification, by defining how fragments of an XML document can be extracted and inserted in a harmless way (i.e., preserving the validity of the XML document itself), will enable our system to extract/insert tuples representing a fragment of a large document in a consistent way. Strictly related, the XLink and XPointer specifications, by ruling the connections between different (parts of) XML documents, will possibly lead to richer and more complex tuple types.
Acknowledgments: Work supported by the Italian Ministero dell'Università e della Ricerca Scientifica e Tecnologica (MURST) in the framework of the Project "MOSAICO: Design Methodologies and Tools of High Performance Systems for Distributed Applications".
[1] Abraham J., Le H., Cedro C., 1999, “XML Repository In T Spaces & UIA Event Notification Application”, http://www.cse.scu.edu/projects/1998-99/project19.
[2] Ahuja S., Carriero N., Gelernter D., 1986, “Linda and Friends”, IEEE Computer, Vol. 19, No. 8, pp. 26-34.
[3] Cabri, G., Leonardi L., Zambonelli F., 1998, “Reactive Tuple Spaces for Mobile Agent Coordination”, 2nd International Workshop on Mobile Agents, LNCS, No. 1477, pp. 237-248, Springer-Verlag (D). Extended version to appear in IEEE Internet Computing.
[4] Cabri, G., Leonardi L., Zambonelli F., 1999, “Coordination Models for Internet Applications based on Mobile Agents”, IEEE Computer Magazine, to appear.
[5] Microsoft Corporation, 1997, Channel Definition Format, http://www.w3.org/TR/NOTE-CDFsubmit.html.
[6] Ciancarini P., Tolksdorf R., Vitali F., Rossi D., Knoche A., 1998, “Coordinating Multi-Agents Applications on the WWW: a Reference Architecture”, IEEE Transactions on Software Engineering, Vol. 24, No. 8, pp. 362-375.
[7] Denti E., Natali A., Omicini A., 1998, “On the Expressive Power of a Language for Programmable Coordination Media”, 1998 ACM Symposium on Applied Computing, Atlanta (G).
[8] Fuggetta A., Picco G., Vigna G., 1998, “Understanding Code Mobility”, IEEE Transactions on Software Engineering, Vol. 24, No. 5, pp. 352-361.
[9] Gelernter D., Carriero N., 1992, “Coordination Languages and Their Significance”, Communications of the ACM, Vol. 35, No. 2, pp. 96-107.
[10] IBM, 1998, T Spaces Home Page, http://www.almaden.ibm.com/Tspaces.
[11] Sun Microsystems, 1998, JavaSpaces Technology, http://java.sun.com/products/javaspaces
[12] Karnik N. M., Tripathi A. R., 1998, “Design Issues in Mobile-Agent Programming Systems”, IEEE Concurrency, Vol. 6, No. 3, pp. 52-61.
[13] Minsky N. H., Leichter J. , 1994, “Law-Governed Linda as a Coordination Model”, Object-Based Models and Languages, Lecture Notes in Computer Science, No. 924, Springer-Verlag (D), pp.125-145.
[14] OMG, 1997, CORBA 2.1 specifications, http://www.omg.org.
[15] Omicini A., Zambonelli F., 1999, “Coordination for Internet Application Development”, Journal of Autonomous Agents and Multi-agent Systems, Vol. 2, No. 3, pp. 251-269.
[16] Papadopoulos G. A., Arbab F., 1998, “Coordination Models and Languages”, Advances in Computers, Vol. 46, pp. 329-400, Academic Press.
[17] Picco G. P., Murphy A. L., Catalin Roman G., 1999, “Lime: Linda Meets Mobility”, International Conference on Software Engineering, Los Angeles (CA).
[18] Tauber J., 1999, “XML after 1.0: You Ain’t Seen Nothin’ Yet”, IEEE Internet Computing, Vol. 3, No. 3, pp. 100-102.
[19] The World Wide Web Consortium, eXtensible Markup Language pages, http://www.w3.org/XML.
[20] The World Wide Web Consortium, eXtensible Stylesheet Language pages, http://www.w3.org/Style/XSL.